

When servers are down, it can lead to interruptions to your business objectives and result in loss of revenue. For example, an airline might not be able to book flights for customers if instances and databases are not available. Systems can fail for a variety of reasons, such as fire, human errors, computer failures, disk failures, and programming errors.
To avoid disruptions and ensure that there is continuity in business services, it is extremely important to have high availability (HA) and disaster recovery (DR) strategies in place. HA and DR are often discussed together. HA is concerned with reducing server downtime as much as possible, but because no system is perfect, DR focuses on the process of using the backup media to recover lost data in the event that the database system does go down.
AlwaysOn is a brand/marketing term used since SQL Server 2012 to describe Microsoft’s enhanced HADR features. Before AlwaysOn, the database engine supported other, built-in proprietary solutions, such as database mirroring, failover cluster, and log shipping. However, each of those techniques came with benefits and limitations. Often, depending on its goals, an organization had to combine multiple methods together to achieve a desirable HADR strategy.
AlwaysOn features were introduced so you don’t have to deal with extra time and resources to implement and introduce complexity in deployment to account for both server and database redundancy, run into problems with scaling, or have standby hardware that is not being efficiently used. These features conveniently blend many of the old practices together and improve areas where they fell short. To truly understand the value of AlwaysOn offerings, it is important to revisit the initial foundational concepts of how the database engine ensured system HADR in the past.
Database Mirroring
Database redundancy can be accomplished through mirroring. For example, you can have a revenue-generating, front-end client app that allows students to order textbooks online. A customer selects their purchase, and requests are made against the PsychologyBooks database on the back end. In the event of a disaster that renders the PsychologyBooks database unavailable, the student will not be able to complete their order.
To avoid this disruption, you can have a principal instance deployed out in production that contains the PsychologyBooks database and have an extra copy of that PsychologyBooks database on a mirrored server on standby. Client apps can reconnect to the mirrored copy instead of experiencing interruption and having to wait for recovery to conclude on the primary. The copy keeps up with the changes made on the original by receiving transaction logs and then redoing those recorded changes.
Mirroring sessions can operate in different modes depending on performance or high-safety justifications. Conveniently, automatic failover is supported when the mirroring session is operated in high-safety synchronous mode and quorum consensus is established with the presence of an optional witness server.
Despite the benefits of mirroring, it falls short because it only provides database redundancy, not server redundancy. That means if the primary server instance goes down, both instances will go down, and it won’t matter that there is a spare copy of the data at the database level. The standby does not support user operations, and snapshots would be needed to get a read-only copy of the data on the mirrored instance. The database is protected, but the server-level objects, such as server role membership, login information, and agent jobs, are not.
For example, if there was a large marketing team and each member had their own login, they would have to go through the process of recreating logins for each person all over again. When failover does occur, it’s on an independent database basis and not as a group.
Failover Clustering
Failover clustering offers redundancy at the instance level and provides protection from hardware and operating system failures. For example, say a node in Queen Anne catches on fire, causing an equipment failure. The entire instance—which includes instance-level objects, such as logins or specific jobs that were created to carry out specific tasks—will be protected and can automatically restart on another node belonging to the cluster. Client apps and services will continue to be available to customers.
The above scenario works because storage is shared between redundant physical servers in a Windows Server Failover Cluster group (WSFC). Both the OS and SQL Server work together so that only one node owns the WSFC resource group at a time.
Unfortunately, with a common storage, this solution does not provide the database redundancy that the earlier mirroring strategy provided. Having a shared storage introduces risk because it results in a single point of failure. For example, the external disks may contain the only copy of the important PsychologyBooks database and, despite the instance being successfully failed over to the Ballard node, there would still be interruption to business goals if the only storage component was compromised. Failover clustering also proposes constraints in terms of scalability because client apps are not able to handle a growing amount of work that expands farther than the cluster.
Log Shipping
Another method to achieve database redundancy is through log shipping. Transaction logs are backed up on the primary server and sent to one or many secondary servers to be restored. Unlike mirroring, the secondary database(s) can be eligible for read-only activity, and the log shipping frequency can be configured for different intervals. There is a performance benefit in scenarios in which secondary databases do not necessarily need to be in sync with the primary database in real time.
For example, running a statistical summary report at the end of the night to see what psychology books are sold throughout the day does not require the copy database to be exactly in sync with the primary database. Read-intensive activity places locks on database objects and can drive up wait times. Therefore, running reporting on a secondary server would relieve the workload demand on the primary revenue-generating server.
The drawback is that log shipping does not support automatic failover. Therefore, if the source server fails, the database needs to be recovered manually. Like mirroring, log shipping does not provide server redundancy and is a database-level solution.
Understanding AlwaysOn
Old technologies each have their benefits and tradeoffs. But implementing a customized HADR solution can quickly become complicated and require more management as these different strategies are arbitrarily mixed and matched together to meet business needs. Therefore, the AlwaysOn features were introduced and provide an enhanced, already combined version of previous strategies.
SQL Server offers two features: AlwaysOn Availability Groups (AG) and AlwaysOn Failover Cluster Instances (FCI). Both require Windows Server Failover Clustering (WSFC) to be implemented.
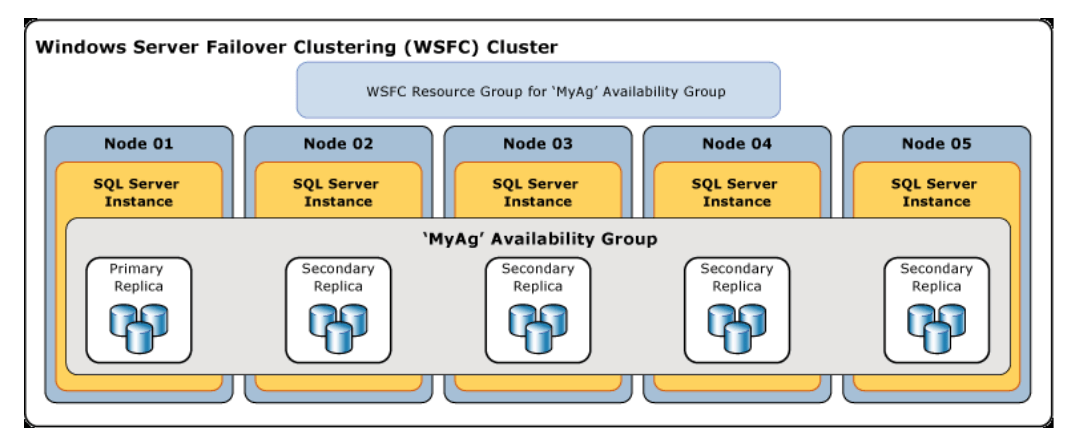
An AG is a group of databases that will failover together. You will need several redundant physical nodes with a SQL Server instance installed on each of the nodes to host the availability replicas. Each replica must be on a different node of the same WSFC. In the schematic above, the primary replica is hosted on Node 01, and all the other secondary replicas are eligible for failover when WSFC senses there is a problem.
The way the secondary replicas stay in sync with the primary is by sending transaction logs and redoing the changes. AG supports both asynchronous and synchronous commit mode. The primary replica is eligible for read and write, whereas the secondary replicas are eligible for read only. Backups can be performed on the secondary location.
Immediately, there are benefits with AlwaysOn AG. Recall from earlier that some of the flaws with database mirroring are that a database can only be mirrored to one secondary server and that when failover occurs, each database is mirrored independently. With AG, databases are made redundant in many places, such as Node 02, Node 03, Node 04, and Node 05 in the example above. Database availability support allows up to nine availability replicas.
Furthermore, log shipping would be necessary to achieve read-only data on the secondary server. But with AG, read-only data is already accounted for. Read-intensive activities such as reporting can be performed on any of the secondary replicas. Also note that there is not a shared storage constraint.
However, AG can be combined with AlwaysOn FCI to allow server redundancy. An FCI instance may be used to host the availability replicas so that server-level objects such as logins and agent jobs may also be protected. This approach will require shared storage. However, inconveniences such as having to perform reconfigurations for the client apps will be eliminated.





