

This is part of a SQL Server Internals Problematic Operators series. To read the first post, click here.
SQL Server has been around over 30 years, and I’ve been working with SQL Server for almost as long. I’ve seen a lot of changes over the years (and decades!) and versions of this incredible product. In these posts, I’ll share with you how I look at some of the features or aspects of SQL Server, sometimes along with a bit of historical perspective.
Last time, I talked about a scan operation in a SQL Server query plan as a potentially problematic operator in SQL Server diagnostixs. Although scans frequently are used only because there is no useful index, there are times when the scan is actually a better choice than an index seek operation.
In this article, I’ll tell you about another family of operators that occasionally is seen as problematic: hashing. Hashing is a very well-known data processing algorithm that has been around for many decades. I studied it in my data structures classes way back when I was first studying computer science at the University. If you’d like background information on hashing and hash functions, you can check out this article on Wikipedia. However, SQL Server didn’t add hashing to its repertoire of query processing options until SQL Server 7. (As an aside, I’ll mention that SQL Server did use hashing in some of its own internal searching algorithms. As the Wikipedia article mentions, hashing uses a special function to map data of arbitrary size to data of a fixed size. SQL used hashing as a search technique to map each page from a database of arbitrary size to a buffer in memory, which is a fixed size. In fact, there used to be an option for sp_configure called ‘hash buckets’, that allowed you to control the number of buckets used for the hashing of database pages into memory buffers.)
What is Hashing?
Hashing is a searching technique that doesn’t require the data to be ordered. SQL Server can use it for JOIN operations, aggregation operations (DISTINCT or GROUP BY) or UNION operations. What these three operations have in common, is that during execution, the query engine is looking for matching values. In a JOIN, we want to find rows in one table (or rowset) that have matching values with rows in another. (And yes, I’m aware of joins that aren’t comparing rows based on equality, but those non-equijoins are irrelevant for this discussion.) For GROUP BY, we find matching values to include in the same group, and for UNION and DISTINCT, we look for matching values in order to exclude them. (Yes, I know UNION ALL is an exception.)
Prior to SQL Server 7, the only way these operations could find matching values easily was if the data was sorted. So, if there was no existing index that maintained the data in sorted order, the query plan would add a SORT operation to the plan. Hashing organizes your data for efficient searching by putting all the rows that have the same result from the internal hash function into the same ‘hash bucket’.
For a more detailed explanation of SQL Server’s hash JOIN operation, including diagrams, take a look at this blog post from SQL Shack.
Once hashing became an option, SQL Server didn’t completely disregard the possibility of sorting data before joining or aggregation, but it just became a possibility for the optimizer to consider. In general, however, if you are trying to join, aggregate or perform UNION on unsorted data, the optimizer will usually choose a hash operation. So many people assume that a HASH JOIN (or other HASH operation) in a plan means you don’t have appropriate indexes and that you should build appropriate indexes to avoid the hash operation.
Let’s look at an example. I’ll first create two unindexed tables.
USE AdventureWorks2016 GO DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
Now, I’ll join these two tables together and filter the rows in the Details table:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID
WHERE SalesOrderDetailID < 100;
Quest Spotlight Tuning Pack doesn’t seem to indicate the hash join as a problem. It only highlights the two table scans.
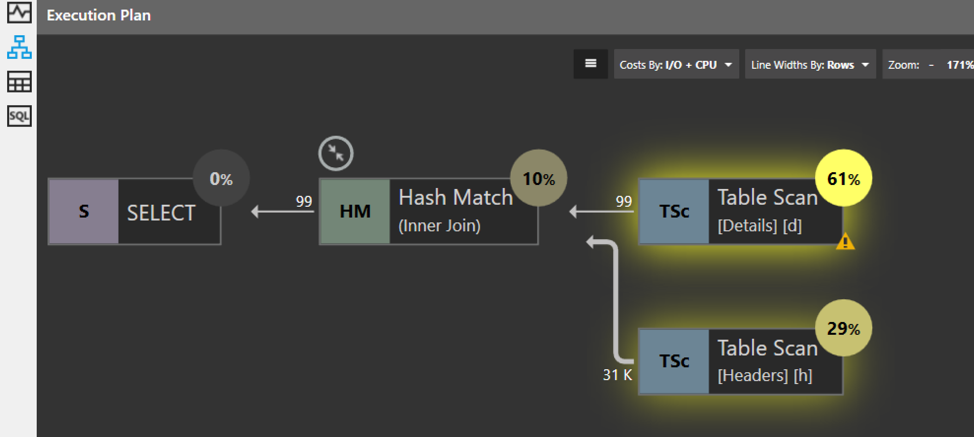
The suggestions recommend building an index on each table that includes every single non-key column as an INCLUDED column. I rarely take those recommendations (as I mentioned in my previous post). I’ll build just the index on the Details table, on the join column, and not have any included columns.
CREATE INDEX Header_index on Headers(SalesOrderID);
Once that index is built the HASH JOIN goes away. The index sorts the data in the Headers table and allows SQL Server to find the matching rows in the inner table using the sort sequence of the index. Now, the most expensive part of the plan is the scan on the outer table (Details) which could be reduced by building an index on the SalesOrderID column in that table. I’ll leave that as an exercise for the reader.
However, a plan with a HASH JOIN is not always a bad thing. The alternative operator (except in special cases) is a NESTED LOOPS JOIN, and that is usually the choice when good indexes are present. However, a NESTED loops operation requires multiple searches of the inner table. The following pseudocode shows the nested loops join algorithm:
for each row R1 in the outer table
for each row R2 in the inner table
if R1 joins with R2
return (R1, R2)
As the name indicates, a NESTED LOOP JOIN is performed as a nested loop. The search of the inner table usually will be performed multiple times, once for each qualifying row in the outer table. Even if there are just a few percent of the rows qualifying, if the table is very large (perhaps in the hundreds of millions, or billions, or rows) that will be a lot of rows to read. In a system that is I/O bound, these millions or billions of reads can be a real bottleneck.
A HASH JOIN, on the other hand, does not do multiple reads of either table. It reads the outer table once to create the hash buckets, and then it reads the inner table once, checking the hash buckets to see if there is a matching row. We have an upper limit of a single pass through each table. Yes, there are CPU resources needed to compute the hash function and manage the buckets’ contents. There are memory resources needed to store the hashed information. But, if you’ve got an I/O bound system, you may have memory and CPU resources to spare. HASH JOIN can be a reasonable choice for the optimizer in these situations where your I/O resources are limited and you are joining very large tables.
Here is pseudocode for the hash join algorithm:
for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the appropriate hash bucket
end
for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
for each row R1 in the corresponding hash bucket
if R1 joins with R2
output (R1, R2)
end
As mentioned earlier, hashing also can be used for aggregation (as well as UNION) operations. Again, if there is a useful index that already has the data sorted, grouping the data can be done very efficiently. However, there are also many situations where hashing is not a bad operator at all. Consider a query like the following, which groups the data in the Details table (created above) by the ProductID column. There are 121,317 rows in the table and only 266 different ProductID values.
SELECT ProductID, count(*)
FROM Details
GROUP BY ProductID;
GO
Using Hashing Operations
To use hashing, SQL Server only has to create and maintain 266 buckets, which isn’t a whole lot. In fact, Quest Spotlight Tuning Pack doesn’t indicate that are any problems with this query.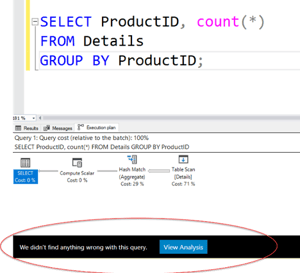
Yes, it has to do a table scan, but that’s because we need to examine every row in the table, and we know that scans are not always a bad thing. An index would only help with the presorting of the data, but using hash aggregation for such a small number of groups will still usually give reasonable performance even with no useful index available.
Like table scans, hashing operations are frequently seen as a ‘bad’ operator to have in a plan. There are cases where you can greatly improve performance by adding useful indexes to remove the hash operations, but that is not always true. And if you are trying to limit the number of indexes on tables that are heavily updated, you should be aware that hash operations are not always something that has to be ‘fixed’, so leaving the query to use a hash can be a reasonable thing to do. In addition, for certain queries on large tables running on I/O bound systems, hashing can actually give better performance than alternative algorithms because of the limited number of reads that need to be performed. The only way to know for sure, it to test various possibilities on your system, with your queries and your data.
In the following post in this series, I’ll tell you about other problematic operators that might show up in your query plans, so check back soon!






