

Database indexes are used to improve the speed of database operations in a table with a large number of records. Database indexes (both clustered indexes and non-clustered indexes) are quite similar to book indexes in their functionality. A book index allows you to go straight to the different topics discussed in the book. If you want to search for a specific topic, you just go to index, find the page number that contains the topic that you are looking for and then can go straight to that page. Without an index, you would have to search the whole book.
Database indexes work in the same way. Without indexes you would have to search the whole table in order to perform a specific database operation. With indexes, you do not have to scan through all the table records. The index points you directly to the record that you are searching for, significantly reducing your query execution time.
SQL Server indexes can be divided into two main types:
- Clustered Indexes
- Non-Clustered Indexes
In this article, we will look at what clustered and non-clustered index are, how they are created and what the main differences between the two are. We will also look at when to use clustered or non-clustered indexes in SQL Server.
Let’s first start with a clustered index.
Clustered Index
A clustered index is an index which defines the physical order in which table records are stored in a database. Since there can be only one way in which records are physically stored in a database table, there can be only one clustered index per table. By default a clustered index is created on a primary key column.
Default Clustered Indexes
Let’s create a dummy table with primary key column to see the default clustered index. Execute the following script:
CREATE DATABASE Hospital
CREATE TABLE Patients
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL
)
The above script creates a dummy database Hospital. The database has 4 columns: id, name, gender, age. The id column is the primary key column. When the above script is executed, a clustered index is automatically created on the id column. To see all the indexes in a table, you can use the “sp_helpindex” stored procedure.
USE Hospital
EXECUTE sp_helpindex Patients
Here is the output:

You can see the index name, description and the column on which the index is created. If you add a new record to the Patients table, it will be stored in ascending order of the value in the id column. If the first record you insert in the table has an id of three, the record will be stored in the third row instead of the first row since clustered index maintains physical order.
Custom Clustered Indexes
You can create your own clustered indexes. However, before you can do that you have to create the existing clustered index. We have one clustered index due to primary key column. If we remove the primary key constraint, the default cluster will be removed. The following script removes the primary key constraint.
USE Hospital
ALTER TABLE Patients
DROP CONSTRAINT PK__Patients__3213E83F3DFAFAAD
GO
The following script creates a custom index “IX_tblPatient_Age” on the age column of the Patients table. Owing to this index, all the records in the Patients table will be stored in ascending order of the age.
use Hospital
CREATE CLUSTERED INDEX IX_tblPatient_Age
ON Patients(age ASC)
Let’s now add a few dummy records in the Patients table to see if they are actually inserted in the ascending order of age:
USE Hospital
INSERT INTO Patients
VALUES
(1, 'Sara', 'Female', 34),
(2, 'Jon', 'Male', 20),
(3, 'Mike', 'Male', 54),
(4, 'Ana', 'Female', 10),
(5, 'Nick', 'Female', 29)
In the above script, we add 5 dummy records. Notice the values for the age column. They have random values and are not in any logical order. However, since we have created a clustered index, the records will be actually inserted in the ascending order of the value in the age column. You can verify this by selecting all the records from the Patients table.
SELECT * FROM Patients
Here is the output:
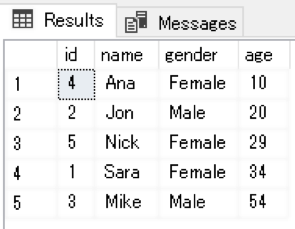
You can see that records are ordered in the ascending order of the values in the age column.
Non-Clustered Indexes
A non-clustered index is also used to speed up search operations. Unlike a clustered index, a non-clustered index doesn’t physically define the order in which records are inserted into a table. In fact, a non-clustered index is stored in a separate location from the data table. A non-clustered index is like a book index, which is located separately from the main contents of the book. Since non-clustered indexes are located in a separate location, there can be multiple non-clustered indexes per table.
To create a non-clustered index, you have to use the “CREATE NONCLUSTERED” statement. The rest of the syntax remains the same as the syntax for creating a clustered index. The following script creates a non-clustered index “IX_tblPatient_Name” which sorts the records in ascending order of the name.
use Hospital
CREATE NONCLUSTERED INDEX IX_tblPatient_Name
ON Patients(name ASC)
The above script will create an index which contains the names of the patients and the address of their corresponding records as shown below:
| Name | Record Address |
| Ana | Record Address |
| Jon | Record Address |
| Mike | Record Address |
| Nick | Record Address |
| Sara | Record Address |
Here, the “Record address” in each row is the reference to the actual table records for the Patients with corresponding names.
For example, if you want to retrieve age and gender of the patient named “Mike”, the database will first search “Mick” in the non-clustered index “IX_tblPatient_Name” and from the non-clustered index it will fetch the actual record reference and will use that to return actual age and gender of the Patient named “Mike”
Since a database has to make two searches, first in the non-clustered index and then in the actual table, non-clustered indexes can be slower for search operations. However, for INSERT and UPDATE operations, non-clustered indexes are faster since the order of the records only needs to be updated in the index and not in the actual table.
When to Use Clustered or Non-Clustered Indexes
Now that you know the differences between a clustered and a non-clustered index, let’s see the different scenarios for using each of them.
1. Number of Indexes
This is pretty obvious. If you need to create multiple indexes on your database, go for non-clustered index since there can be only one clustered index.
2. SELECT Operations
If you want to select only the index value that is used to create and index, non-clustered indexes are faster. For example, if you have created an index on the “name” column and you want to select only the name, non-clustered indexes will quickly return the name.
However, if you want to select other column values such as age, gender using the name index, the SELECT operation will be slower since first the name will be searched from the index and then the reference to the actual table record will be used to search the age and gender.
On the other hand, with clustered indexes since all the records are already sorted, the SELECT operation is faster if the data is being selected from columns other than the column with clustered index.
3. INSERT/UPDATE Operations
The INSERT and UPDATE operations are faster with non-clustered indexes since the actual records are not required to be sorted when an INSERT or UPDATE operation is performed. Rather only the non-clustered index needs updating.
4. Disk Space
Since, non-clustered indexes are stored at a separate location than the original table, non-clustered indexes consume additional disk space. If disk space is a problem, use a clustered index.
5. Final Verdict
As a rule of thumb, every table should have at least one clustered index preferably on the column that is used for SELECTING records and contains unique values. The primary key column is an ideal candidate for a clustered index.
On the other hand columns that are often involved in INSERT and UPDATE queries should have a non-clustered index assuming that disk space isn’t a concern.





